Putting the “You” in CPU의 일부: 컴퓨터가 프로그램을 실행하는 방법에 대한 심층 탐구.
챕터 4:
엘프 로드가 되다
GitHub에서 수정
우리는 이제 execve를 꽤 철저하게 이해했습니다. 대부분의 경로의 끝에서 커널은 실행할 기계어를 포함하는 최종 프로그램에 도달할 것입니다. 일반적으로, 실제로 코드로 점프하기 전에 설정 프로세스가 필요합니다 — 예를 들어, 프로그램의 다른 부분들이 메모리의 올바른 위치에 로드되어야 합니다. 각 프로그램은 다른 것들을 위해 다른 양의 메모리가 필요하므로, 실행을 위해 프로그램을 설정하는 방법을 지정하는 표준 파일 형식이 있습니다. Linux는 많은 그러한 형식을 지원하지만, 가장 일반적인 형식은 단연코 ELF (executable and linkable format)입니다.

(Nicky Case에게 사랑스러운 그림을 그려주셔서 감사합니다.)
참고: 엘프는 어디에나 있나요?
Linux에서 앱이나 명령줄 프로그램을 실행할 때, 그것이 ELF 바이너리일 가능성이 매우 높습니다. 그러나 macOS에서는 사실상의 형식이 Mach-O입니다. Mach-O는 ELF와 모든 동일한 작업을 수행하지만 다르게 구조화되어 있습니다. Windows에서 .exe 파일은 Portable Executable 형식을 사용하며, 이것은 또한 동일한 개념을 가진 다른 형식입니다.
Linux 커널에서 ELF 바이너리는 binfmt_elf 핸들러에 의해 처리되며, 이것은 많은 다른 핸들러보다 더 복잡하고 수천 줄의 코드를 포함합니다. 이것은 ELF 파일에서 특정 세부 사항을 파싱하고 프로세스를 메모리에 로드하고 실행하는 데 사용하는 책임이 있습니다.
줄 수로 binfmt 핸들러를 정렬하기 위해 일부 명령줄 kung fu를 실행했습니다:
$ wc -l binfmt_* | sort -nr | sed 1d
2181 binfmt_elf.c
1658 binfmt_elf_fdpic.c
944 binfmt_flat.c
836 binfmt_misc.c
158 binfmt_script.c
64 binfmt_elf_test.c파일 구조
binfmt_elf가 ELF 파일을 실행하는 방법을 더 깊이 살펴보기 전에, 파일 형식 자체를 살펴봅시다. ELF 파일은 일반적으로 네 부분으로 구성됩니다:

ELF 헤더
모든 ELF 파일에는 ELF 헤더가 있습니다. 이것은 다음과 같은 바이너리에 대한 기본 정보를 전달하는 매우 중요한 작업을 가지고 있습니다:
- 실행되도록 설계된 프로세서. ELF 파일은 ARM 및 x86과 같은 다른 프로세서 유형에 대한 기계어를 포함할 수 있습니다.
- 바이너리가 실행 파일로 자체적으로 실행되도록 의도되었는지, 아니면 다른 프로그램에 의해 “동적으로 링크된 라이브러리”로 로드되도록 의도되었는지. 동적 링킹이 무엇인지 곧 자세히 살펴보겠습니다.
- 실행 파일의 진입점. 나중 섹션은 ELF 파일에 포함된 데이터를 메모리에 정확히 어디에 로드할지 지정합니다. 진입점은 전체 프로세스가 로드된 후 메모리에서 첫 번째 기계어 명령어가 있는 위치를 가리키는 메모리 주소입니다.
ELF 헤더는 항상 파일의 시작 부분에 있습니다. 파일 내 어디에나 있을 수 있는 프로그램 헤더 테이블과 섹션 헤더의 위치를 지정합니다. 그 테이블들은 차례로 파일의 다른 곳에 저장된 데이터를 가리킵니다.
프로그램 헤더 테이블
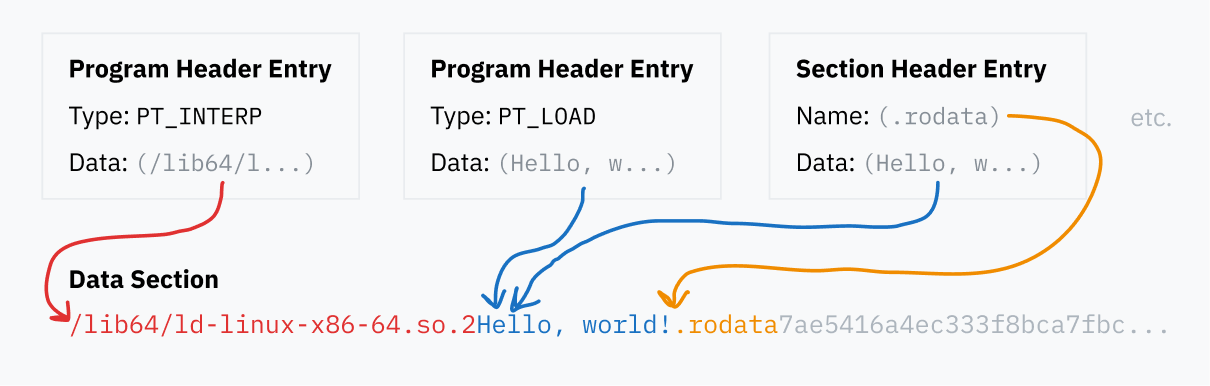
프로그램 헤더 테이블은 런타임에 바이너리를 로드하고 실행하는 방법에 대한 특정 세부 사항을 포함하는 일련의 항목입니다. 각 항목에는 지정하는 세부 사항을 나타내는 유형 필드가 있습니다 — 예를 들어, PT_LOAD는 메모리에 로드되어야 하는 데이터를 포함함을 의미하지만, PT_NOTE는 세그먼트가 반드시 어디에나 로드될 필요가 없는 정보 텍스트를 포함함을 의미합니다.

각 항목은 데이터가 파일의 어디에 있는지, 그리고 때때로 데이터를 메모리에 로드하는 방법에 대한 정보를 지정합니다:
- ELF 파일 내에서 데이터의 위치를 가리킵니다.
- 데이터가 로드되어야 하는 가상 메모리 주소를 지정할 수 있습니다. 이것은 일반적으로 세그먼트가 메모리에 로드되도록 의도되지 않은 경우 비어 있습니다.
- 두 필드는 데이터의 길이를 지정합니다: 하나는 파일의 데이터 길이를 위한 것이고, 하나는 생성될 메모리 영역의 길이를 위한 것입니다. 메모리 영역 길이가 파일의 길이보다 길면, 추가 메모리는 0으로 채워집니다. 이것은 런타임에 사용할 정적 메모리 세그먼트를 원할 수 있는 프로그램에 유익합니다; 이러한 빈 메모리 세그먼트는 일반적으로 BSS 세그먼트라고 불립니다.
- 마지막으로, 플래그 필드는 메모리에 로드된 경우 허용되어야 하는 작업을 지정합니다:
PF_R은 읽을 수 있게 만들고,PF_W는 쓸 수 있게 만들며,PF_X는 CPU에서 실행될 수 있어야 하는 코드임을 의미합니다.
섹션 헤더 테이블
섹션 헤더 테이블은 섹션에 대한 정보를 포함하는 일련의 항목입니다. 이 섹션 정보는 지도와 같아서 ELF 파일 내부의 데이터를 도식화합니다. 디버거와 같은 프로그램이 데이터의 다른 부분의 의도된 용도를 쉽게 이해할 수 있게 합니다.
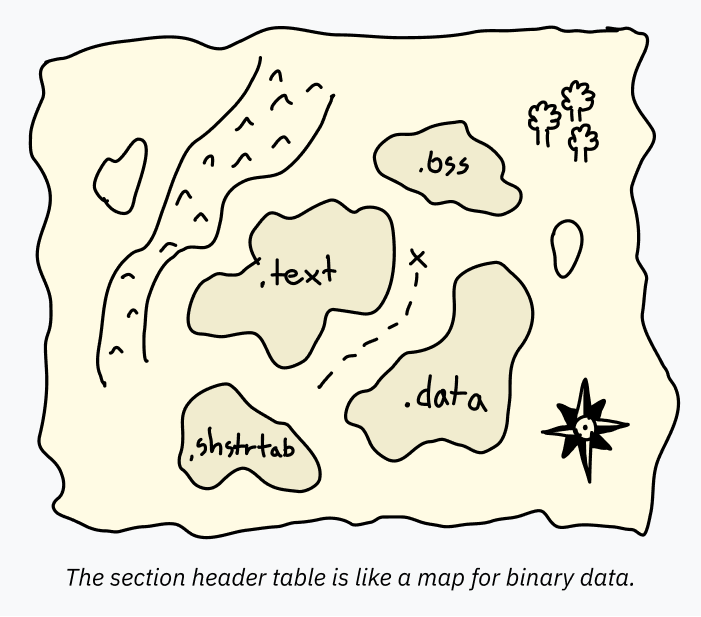
예를 들어, 프로그램 헤더 테이블은 함께 메모리에 로드될 대용량 데이터 덩어리를 지정할 수 있습니다. 그 단일 PT_LOAD 블록은 코드와 전역 변수를 모두 포함할 수 있습니다! 프로그램을 실행하기 위해 별도로 지정할 필요가 없습니다; CPU는 진입점에서 시작하여 앞으로 나아가며, 프로그램이 요청하는 곳에서 데이터에 액세스합니다. 그러나 프로그램을 분석하기 위한 디버거와 같은 소프트웨어는 각 영역이 정확히 어디에서 시작하고 끝나는지 알아야 하며, 그렇지 않으면 “hello”라고 말하는 텍스트를 코드로 디코딩하려고 시도할 수 있습니다 (그리고 그것은 유효한 코드가 아니므로 폭발합니다). 이 정보는 섹션 헤더 테이블에 저장됩니다.
일반적으로 포함되지만, 섹션 헤더 테이블은 실제로 선택 사항입니다. ELF 파일은 섹션 헤더 테이블이 완전히 제거되어도 완벽하게 실행될 수 있으며, 코드가 무엇을 하는지 숨기려는 개발자는 때때로 의도적으로 ELF 바이너리에서 섹션 헤더 테이블을 제거하거나 손상시켜 디코딩을 더 어렵게 만듭니다.
각 섹션에는 이름, 유형, 그리고 사용 및 디코딩 방법을 지정하는 일부 플래그가 있습니다. 표준 이름은 관례적으로 점으로 시작합니다. 가장 일반적인 섹션은 다음과 같습니다:
.text: CPU에서 메모리에 로드되어 실행될 기계어. 실행 가능하다고 표시하기 위한SHF_EXECINSTR플래그와 실행을 위해 메모리에 로드된다는 의미의SHF_ALLOC플래그가 있는SHT_PROGBITS유형입니다. (이름에 속지 마세요, 여전히 그냥 바이너리 기계어입니다! 읽을 수 있는 “텍스트”가 아님에도.text라고 불리는 것이 항상 다소 이상하다고 생각했습니다.).data: 실행 파일에 하드코딩되어 메모리에 로드될 초기화된 데이터. 예를 들어, 일부 텍스트를 포함하는 전역 변수가 이 섹션에 있을 수 있습니다. 저수준 코드를 작성하면, 이것은 정적 변수가 들어가는 섹션입니다. 이것 또한SHT_PROGBITS유형을 가지며, 이것은 단순히 섹션이 “프로그램을 위한 정보”를 포함한다는 것을 의미합니다. 플래그는 쓰기 가능한 메모리로 표시하기 위한SHF_ALLOC과SHF_WRITE입니다..bss: 앞서 0으로 시작하는 할당된 메모리를 갖는 것이 일반적이라고 언급했습니다. ELF 파일에 많은 빈 바이트를 포함하는 것은 낭비이므로, BSS라는 특수 세그먼트 유형이 사용됩니다. 디버깅 중에 BSS 세그먼트에 대해 아는 것이 도움이 되므로, 할당될 메모리의 길이를 지정하는 섹션 헤더 테이블 항목도 있습니다.SHT_NOBITS유형이며,SHF_ALLOC과SHF_WRITE로 플래그가 지정됩니다..rodata: 이것은.data와 같지만 읽기 전용입니다.printf("Hello, world!")를 실행하는 매우 기본적인 C 프로그램에서 “Hello world!” 문자열은.rodata섹션에 있을 것이고, 실제 인쇄 코드는.text섹션에 있을 것입니다..shstrtab: 이것은 재미있는 구현 세부 사항입니다! 섹션의 이름 자체(.text및.shstrtab과 같은)는 섹션 헤더 테이블에 직접 포함되지 않습니다. 대신, 각 항목은 이름을 포함하는 ELF 파일의 위치에 대한 오프셋을 포함합니다. 이렇게 하면, 섹션 헤더 테이블의 각 항목이 동일한 크기가 될 수 있어 파싱하기가 더 쉬워집니다 — 이름에 대한 오프셋은 고정 크기 숫자인 반면, 테이블에 이름을 포함하면 가변 크기 문자열을 사용하게 됩니다. 이 모든 이름 데이터는SHT_STRTAB유형의.shstrtab이라는 자체 섹션에 저장됩니다.
데이터
프로그램 및 섹션 헤더 테이블 항목은 모두 메모리에 로드하거나, 프로그램 코드가 어디에 있는지 지정하거나, 단순히 섹션 이름을 지정하기 위해 ELF 파일 내의 데이터 블록을 가리킵니다. 이러한 다양한 데이터 조각은 모두 ELF 파일의 데이터 섹션에 포함됩니다.
링킹에 대한 간략한 설명
binfmt_elf 코드로 돌아가서: 커널은 프로그램 헤더 테이블의 두 가지 유형의 항목에 관심을 갖습니다.
PT_LOAD 세그먼트는 .text 및 .data 섹션과 같은 모든 프로그램 데이터를 메모리에 어디에 로드해야 하는지 지정합니다. 커널은 ELF 파일에서 이러한 항목을 읽어 CPU에서 프로그램이 실행될 수 있도록 데이터를 메모리에 로드합니다.
커널이 관심을 갖는 다른 유형의 프로그램 헤더 테이블 항목은 “동적 링킹 런타임”을 지정하는 PT_INTERP입니다.
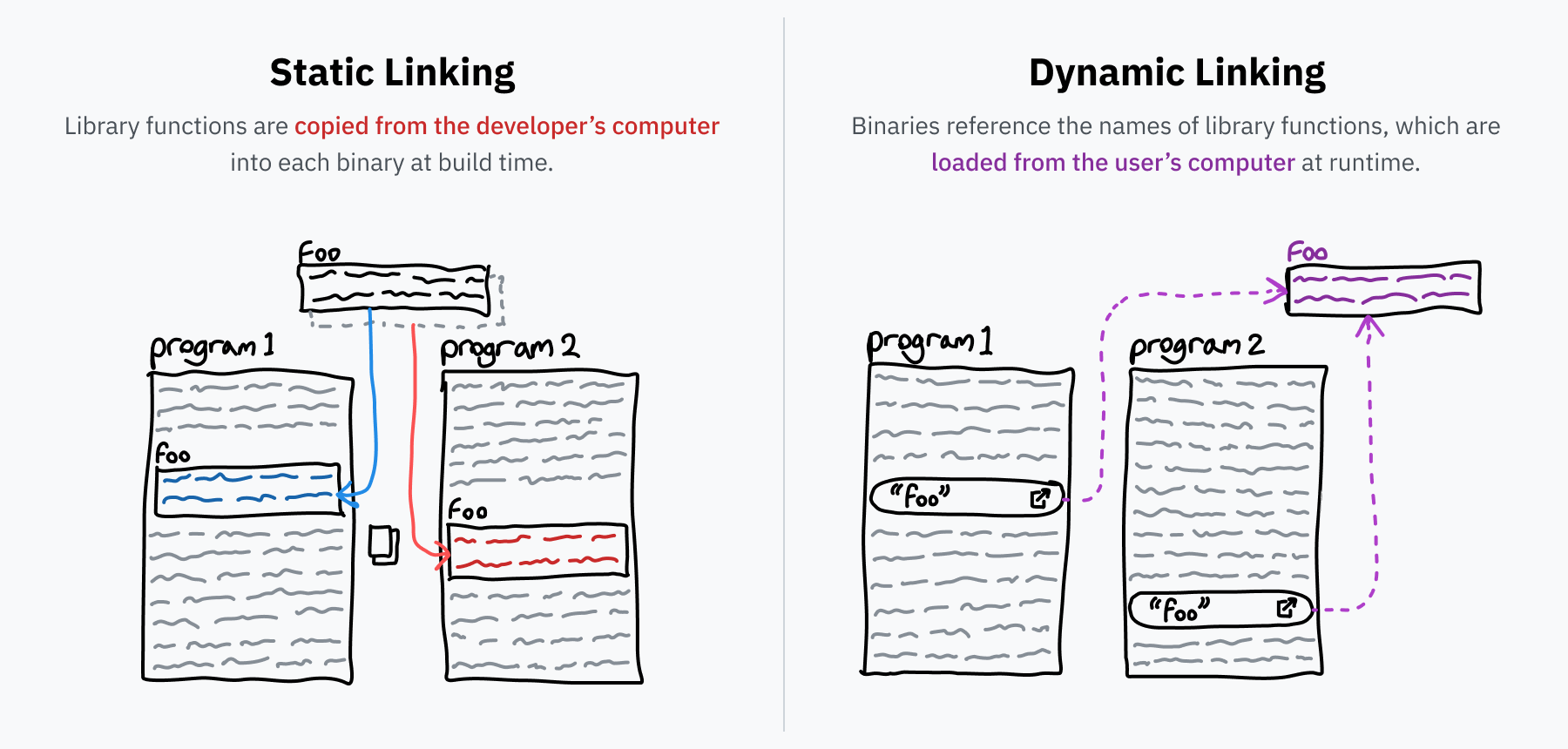
동적 링킹이 무엇인지 이야기하기 전에, 일반적으로 “링킹”에 대해 이야기합시다. 프로그래머는 재사용 가능한 코드 라이브러리 위에 프로그램을 구축하는 경향이 있습니다 — 예를 들어, 앞서 이야기한 libc입니다. 소스 코드를 실행 가능한 바이너리로 변환할 때, 링커라는 프로그램이 라이브러리 코드를 찾고 바이너리에 복사하여 이러한 모든 참조를 해결합니다. 이 프로세스를 정적 링킹이라고 하며, 외부 코드가 배포되는 파일에 직접 포함됨을 의미합니다.
그러나, 일부 라이브러리는 매우 일반적입니다. libc는 기본적으로 태양 아래 모든 프로그램에서 사용되는데, OS와 시스템 콜을 통해 상호 작용하기 위한 표준 인터페이스이기 때문입니다. 컴퓨터의 모든 단일 프로그램에 libc의 별도 복사본을 포함하는 것은 공간의 끔찍한 낭비일 것입니다. 또한, 라이브러리의 버그가 라이브러리를 사용하는 각 프로그램이 업데이트되기를 기다리지 않고 한 곳에서 수정될 수 있다면 좋을 것입니다. 동적 링킹은 이러한 문제에 대한 해결책입니다.
정적으로 링크된 프로그램이 bar라는 라이브러리에서 foo 함수를 필요로 하는 경우, 프로그램은 foo의 전체 복사본을 포함할 것입니다. 그러나 동적으로 링크된 경우 “라이브러리 bar에서 foo가 필요합니다”라는 참조만 포함할 것입니다. 프로그램이 실행될 때, bar가 컴퓨터에 설치되어 있기를 바라며 foo 함수의 기계어를 필요에 따라 메모리에 로드할 수 있습니다. 컴퓨터의 bar 라이브러리 설치가 업데이트되면, 프로그램 자체의 변경 없이 다음에 프로그램이 실행될 때 새 코드가 로드됩니다.
실제로 사용되는 동적 링킹
Linux에서 bar와 같은 동적으로 링크 가능한 라이브러리는 일반적으로 .so (Shared Object) 확장자를 가진 파일로 패키징됩니다. 이러한 .so 파일은 프로그램과 마찬가지로 ELF 파일입니다 — ELF 헤더에 파일이 실행 파일인지 라이브러리인지 지정하는 필드가 포함되어 있음을 기억하실 것입니다. 또한, 공유 객체는 섹션 헤더 테이블에 파일에서 어떤 심볼이 내보내지고 동적으로 링크될 수 있는지에 대한 정보를 포함하는 .dynsym 섹션을 가지고 있습니다.
Windows에서는 bar와 같은 라이브러리가 .dll (dynamic link library) 파일로 패키징됩니다. macOS는 .dylib (dynamically linked library) 확장자를 사용합니다. macOS 앱과 Windows .exe 파일과 마찬가지로, 이것들은 ELF 파일과 약간 다르게 형식화되어 있지만 동일한 개념과 기술입니다.
두 가지 유형의 링킹 사이의 흥미로운 차이점은 정적 링킹을 사용하면 사용되는 라이브러리의 부분만 실행 파일에 포함되어 메모리에 로드된다는 것입니다. 동적 링킹을 사용하면 전체 라이브러리가 메모리에 로드됩니다. 이것은 처음에는 덜 효율적으로 들릴 수 있지만, 실제로는 현대 운영 체제가 라이브러리를 메모리에 한 번 로드한 다음 프로세스 간에 해당 코드를 공유함으로써 더 많은 공간을 절약할 수 있게 합니다. 라이브러리가 다른 프로그램에 대해 다른 상태를 필요로 하므로 코드만 공유할 수 있지만, 절약은 여전히 수십에서 수백 메가바이트의 RAM 정도일 수 있습니다.
실행
커널이 ELF 파일을 실행하는 것으로 다시 돌아가 봅시다: 실행 중인 바이너리가 동적으로 링크된 경우, OS는 바로 바이너리의 코드로 점프할 수 없습니다. 왜냐하면 누락된 코드가 있기 때문입니다 — 기억하세요, 동적으로 링크된 프로그램은 필요한 라이브러리 함수에 대한 참조만 가지고 있습니다!
바이너리를 실행하기 위해, OS는 어떤 라이브러리가 필요한지 파악하고, 그것들을 로드하고, 모든 이름이 지정된 포인터를 실제 점프 명령어로 교체한 다음 실제 프로그램 코드를 시작해야 합니다. 이것은 ELF 형식과 깊이 상호 작용하는 매우 복잡한 코드이므로, 일반적으로 커널의 일부가 아니라 독립 실행형 프로그램입니다. ELF 파일은 프로그램 헤더 테이블의 PT_INTERP 항목에서 사용하려는 프로그램의 경로를 지정합니다(일반적으로 /lib64/ld-linux-x86-64.so.2와 같은 것).
ELF 헤더를 읽고 프로그램 헤더 테이블을 스캔한 후, 커널은 새 프로그램을 위한 메모리 구조를 설정할 수 있습니다. 모든 PT_LOAD 세그먼트를 메모리에 로드하여 시작하며, 프로그램의 정적 데이터, BSS 공간 및 기계어를 채웁니다. 프로그램이 동적으로 링크된 경우, 커널은 ELF 인터프리터 (PT_INTERP)를 실행해야 하므로, 인터프리터의 데이터, BSS 및 코드도 메모리에 로드합니다.
이제 커널은 사용자 공간으로 복귀할 때 복원할 CPU의 명령어 포인터를 설정해야 합니다. 실행 파일이 동적으로 링크된 경우, 커널은 명령어 포인터를 메모리에서 ELF 인터프리터 코드의 시작으로 설정합니다. 그렇지 않으면, 커널은 실행 파일의 시작으로 설정합니다.
커널은 이제 시스템 콜에서 복귀할 준비가 거의 되었습니다 (execve에 있다는 것을 기억하세요). 프로그램이 시작할 때 읽을 수 있도록 argc, argv 및 환경 변수를 스택에 푸시합니다.
레지스터는 이제 지워집니다. 시스템 콜을 처리하기 전에, 커널은 레지스터의 현재 값을 사용자 공간으로 다시 전환할 때 복원되도록 스택에 저장합니다. 사용자 공간으로 복귀하기 전에, 커널은 스택의 이 부분을 0으로 만듭니다.
마지막으로, 시스템 콜이 끝나고 커널은 사용자 공간으로 복귀합니다. 이제 0이 된 레지스터를 복원하고, 저장된 명령어 포인터로 점프합니다. 그 명령어 포인터는 이제 새 프로그램(또는 ELF 인터프리터)의 시작점이며 현재 프로세스가 교체되었습니다!
챕터 5로 계속: 컴퓨터 안의 번역기