Putting the “You” in CPU의 일부: 컴퓨터가 프로그램을 실행하는 방법에 대한 심층 탐구.
챕터 5:
컴퓨터 안의 번역기
GitHub에서 수정
지금까지 메모리를 읽고 쓰는 것에 대해 이야기할 때마다 조금 애매했습니다. 예를 들어, ELF 파일은 데이터를 로드할 특정 메모리 주소를 지정하는데, 서로 다른 프로세스가 충돌하는 메모리를 사용하려고 하는 문제가 발생하지 않는 이유는 무엇일까요? 왜 각 프로세스가 다른 메모리 환경을 가지고 있는 것처럼 보일까요?
또한, 정확히 어떻게 여기까지 왔을까요? execve가 현재 프로세스를 새 프로그램으로 교체하는 시스템 콜이라는 것을 이해했지만, 이것은 여러 프로세스를 시작할 수 있는 방법을 설명하지 않습니다. 첫 번째 프로그램이 어떻게 실행되는지도 확실히 설명하지 않습니다 — 어떤 닭(프로세스)이 다른 모든 알(다른 프로세스들)을 낳습니까(생성합니까)?
우리는 여정의 끝에 가까워지고 있습니다. 이 두 가지 질문에 답하고 나면, 컴퓨터가 부팅에서 지금 사용하고 있는 소프트웨어를 실행하기까지 어떻게 되었는지에 대한 거의 완전한 이해를 갖게 될 것입니다.
메모리는 가짜입니다
그래서… 메모리에 대해. CPU가 메모리 주소를 읽거나 쓸 때, 실제로 물리 메모리(RAM)의 해당 위치를 참조하는 것이 아니라는 것이 밝혀졌습니다. 오히려, 가상 메모리 공간의 위치를 가리키고 있습니다.
CPU는 메모리 관리 장치 (MMU)라는 칩과 통신합니다. MMU는 가상 메모리의 위치를 RAM의 위치로 변환하는 사전을 가진 번역기처럼 작동합니다. CPU가 메모리 주소 0xfffaf54834067fe2에서 읽으라는 명령어를 받으면, MMU에 해당 주소를 변환하도록 요청합니다. MMU는 사전에서 조회하고, 일치하는 물리 주소가 0x53a4b64a90179fe2임을 발견하고, 숫자를 CPU로 다시 보냅니다. 그러면 CPU는 RAM의 해당 주소에서 읽을 수 있습니다.

컴퓨터가 처음 부팅될 때, 메모리 액세스는 물리 RAM으로 직접 이동합니다. 시작 직후, OS는 변환 사전을 만들고 CPU에 MMU 사용을 시작하도록 지시합니다.
이 사전은 실제로 페이지 테이블이라고 불리며, 모든 메모리 액세스를 변환하는 이 시스템을 페이징이라고 합니다. 페이지 테이블의 항목은 페이지라고 불리며 각각은 가상 메모리의 특정 청크가 RAM에 어떻게 매핑되는지를 나타냅니다. 이러한 청크는 항상 고정된 크기이며, 각 프로세서 아키텍처는 다른 페이지 크기를 가지고 있습니다. x86-64는 기본 4 KiB 페이지 크기를 가지며, 이는 각 페이지가 4,096바이트 길이의 메모리 블록에 대한 매핑을 지정함을 의미합니다.
즉, 4 KiB 페이지를 사용하면 주소의 하위 12비트는 MMU 변환 전후에 항상 동일할 것입니다 — 12비트인 이유는 변환 후 얻는 4,096바이트 페이지를 인덱싱하는 데 필요한 비트 수이기 때문입니다.
x86-64는 또한 운영 체제가 더 큰 2 MiB 또는 4 GiB 페이지를 활성화할 수 있게 하며, 이것은 주소 변환 속도를 향상시킬 수 있지만 메모리 단편화와 낭비를 증가시킵니다. 페이지 크기가 클수록, MMU에 의해 변환되는 주소의 일부가 작아집니다.

페이지 테이블 자체는 RAM에 있습니다. 수백만 개의 항목을 포함할 수 있지만, 각 항목의 크기는 몇 바이트 정도에 불과하므로 페이지 테이블은 그다지 많은 공간을 차지하지 않습니다.
부팅 시 페이징을 활성화하기 위해, 커널은 먼저 RAM에 페이지 테이블을 구성합니다. 그런 다음, 페이지 테이블 베이스 레지스터(PTBR)라는 레지스터에 페이지 테이블의 시작 부분의 물리 주소를 저장합니다. 마지막으로, 커널은 MMU로 모든 메모리 액세스를 변환하도록 페이징을 활성화합니다. x86-64에서 제어 레지스터 3(CR3)의 상위 20비트는 PTBR로 기능합니다. 페이징을 위해 지정된 CR0의 비트 31, PG는 페이징을 활성화하기 위해 1로 설정됩니다.
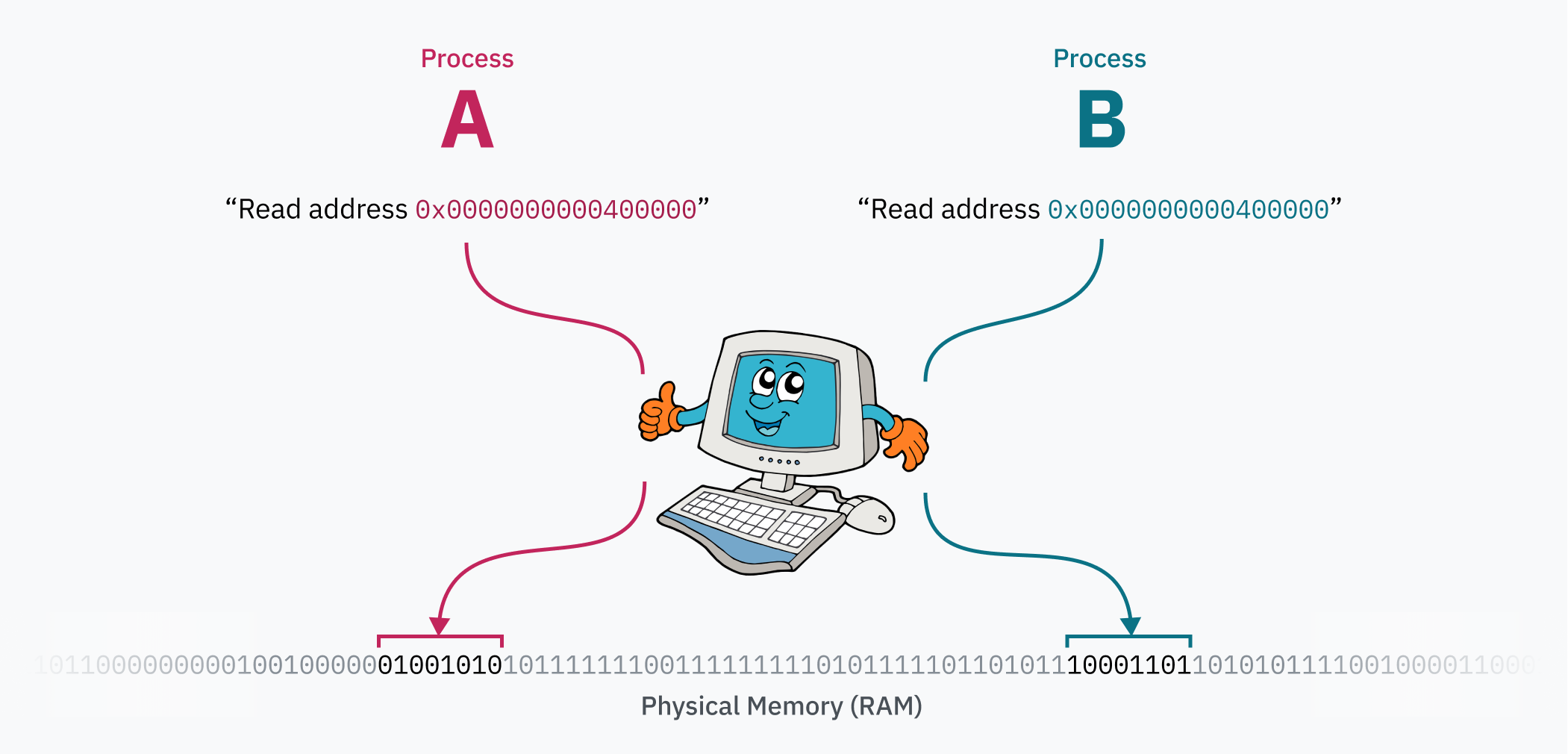
페이징 시스템의 마법은 컴퓨터가 실행되는 동안 페이지 테이블을 편집할 수 있다는 것입니다. 이것이 각 프로세스가 자체 격리된 메모리 공간을 가질 수 있는 방법입니다 — OS가 한 프로세스에서 다른 프로세스로 컨텍스트를 전환할 때, 중요한 작업은 가상 메모리 공간을 물리 메모리의 다른 영역으로 다시 매핑하는 것입니다. 두 프로세스가 있다고 가정해 봅시다: 프로세스 A는 0x0000000000400000에 코드와 데이터(ELF 파일에서 로드되었을 가능성이 높음)를 가질 수 있고, 프로세스 B는 정확히 동일한 주소에서 코드와 데이터에 액세스할 수 있습니다. 이 두 프로세스는 실제로 해당 주소 범위를 두고 싸우지 않기 때문에 동일한 프로그램의 인스턴스일 수도 있습니다! 프로세스 A의 데이터는 물리 메모리에서 프로세스 B로부터 멀리 떨어진 곳에 있으며, 프로세스로 전환할 때 커널에 의해 0x0000000000400000에 매핑됩니다.
참고: 저주받은 ELF 사실
특정 상황에서,
binfmt_elf는 메모리의 첫 번째 페이지를 0으로 매핑해야 합니다. 1988년의 OS이자 ELF를 지원한 최초의 OS인 UNIX System V Release 4.0 (SVr4)용으로 작성된 일부 프로그램은 널 포인터를 읽을 수 있다는 것에 의존합니다. 그리고 어떻게든, 일부 프로그램은 여전히 그 동작에 의존합니다.이것을 구현하는 Linux 커널 개발자가 조금 불만스러웠던 것 같습니다:
“왜 이것을, 물어보시나요??? 글쎄요 SVr4는 페이지 0을 읽기 전용으로 매핑하고, 일부 애플리케이션은 이 동작에 ‘의존’합니다. 이것들을 다시 컴파일할 수 있는 권한이 없기 때문에, 우리는 SVr4 동작을 에뮬레이트합니다. 한숨.”
한숨.
페이징을 통한 보안
메모리 페이징에 의해 활성화된 프로세스 격리는 코드 인체공학을 개선하지만(프로세스가 메모리를 사용하기 위해 다른 프로세스를 인식할 필요가 없음), 보안 수준도 만듭니다: 프로세스는 다른 프로세스의 메모리에 액세스할 수 없습니다. 이것은 이 글의 시작 부분에서 원래 질문 중 하나에 절반 정도 답합니다:
프로그램이 CPU에서 직접 실행되고 CPU가 RAM에 직접 액세스할 수 있다면, 왜 코드가 다른 프로세스의 메모리나, 더 나쁘게는 커널에 액세스할 수 없을까요?
그것을 기억하시나요? 정말 오래전 같네요…
그런데 그 커널 메모리는 어떨까요? 우선: 커널은 명백히 실행 중인 모든 프로세스를 추적하고 심지어 페이지 테이블 자체를 추적하기 위해 자체 데이터를 많이 저장해야 합니다. 하드웨어 인터럽트, 소프트웨어 인터럽트 또는 시스템 콜이 트리거되고 CPU가 커널 모드로 진입할 때마다, 커널 코드는 어떻게든 그 메모리에 액세스해야 합니다.
Linux의 해결책은 항상 가상 메모리 공간의 상위 절반을 커널에 할당하는 것이므로 Linux는 상위 절반 커널이라고 불립니다. Windows는 유사한 기술을 사용하는 반면, macOS는… 약간 더 복잡하여 그것에 대해 읽으면서 제 뇌가 귀 밖으로 흘러나왔습니다. ~(++)~

그러나 사용자 공간 프로세스가 커널 메모리를 읽거나 쓸 수 있다면 보안에 끔찍할 것이므로, 페이징은 두 번째 보안 계층을 활성화합니다: 각 페이지는 권한 플래그를 지정해야 합니다. 한 플래그는 영역이 쓰기 가능한지 또는 읽기 전용인지 결정합니다. 다른 플래그는 CPU에 커널 모드만 영역의 메모리에 액세스할 수 있도록 허용한다고 알립니다. 이 후자의 플래그는 전체 상위 절반 커널 공간을 보호하는 데 사용됩니다 — 전체 커널 메모리 공간은 실제로 사용자 공간 프로그램의 가상 메모리 매핑에서 사용 가능하지만, 액세스 권한이 없습니다.

페이지 테이블 자체는 실제로 커널 메모리 공간 내에 포함되어 있습니다! 타이머 칩이 프로세스 전환을 위한 하드웨어 인터럽트를 트리거하면, CPU는 권한 수준을 커널 모드로 전환하고 Linux 커널 코드로 점프합니다. 커널 모드(Intel 링 0)에 있으면 CPU가 커널로 보호된 메모리 영역에 액세스할 수 있습니다. 그러면 커널은 새 프로세스를 위해 가상 메모리의 하위 절반을 다시 매핑하기 위해 페이지 테이블(메모리의 상위 절반 어딘가에 있음)에 쓸 수 있습니다. 커널이 새 프로세스로 전환하고 CPU가 사용자 모드로 진입하면, 더 이상 커널 메모리에 액세스할 수 없습니다.
거의 모든 메모리 액세스는 MMU를 거칩니다. 인터럽트 디스크립터 테이블 핸들러 포인터? 그것들도 커널의 가상 메모리 공간을 주소로 지정합니다.
계층적 페이징 및 기타 최적화
64비트 시스템은 64비트 길이의 메모리 주소를 가지므로, 64비트 가상 메모리 공간은 무려 16 엑스비바이트의 크기입니다. 이것은 엄청나게 크며, 오늘날 존재하는 컴퓨터나 곧 존재할 컴퓨터보다 훨씬 큽니다. 제가 아는 한, 지금까지 컴퓨터에서 가장 많은 RAM은 Blue Waters 슈퍼컴퓨터에 있었으며, 1.5페타바이트 이상의 RAM을 가지고 있습니다. 그것은 여전히 16 EiB의 0.01% 미만입니다.
가상 메모리 공간의 모든 4 KiB 섹션에 대해 페이지 테이블의 항목이 필요하다면, 4,503,599,627,370,496개의 페이지 테이블 항목이 필요할 것입니다. 8바이트 길이의 페이지 테이블 항목을 사용하면, 페이지 테이블만 저장하는 데 32페비바이트의 RAM이 필요할 것입니다. 이것이 여전히 컴퓨터에서 가장 많은 RAM의 세계 기록보다 크다는 것을 알 수 있습니다.
참고: 왜 이상한 단위를?
흔하지 않고 정말 보기 흉하다는 것을 알고 있지만, 이진 바이트 크기 단위(2의 거듭제곱)와 메트릭 단위(10의 거듭제곱)를 명확하게 구분하는 것이 중요하다고 생각합니다. 킬로바이트, kB는 1,000바이트를 의미하는 SI 단위입니다. 키비바이트, KiB는 1,024바이트를 의미하는 IEC 권장 단위입니다. CPU와 메모리 주소의 관점에서, 바이트 수는 일반적으로 2의 거듭제곱입니다. 왜냐하면 컴퓨터는 이진 시스템이기 때문입니다. KB (또는 더 나쁘게는 kB)를 1,024를 의미하는 데 사용하면 더 모호할 것입니다.
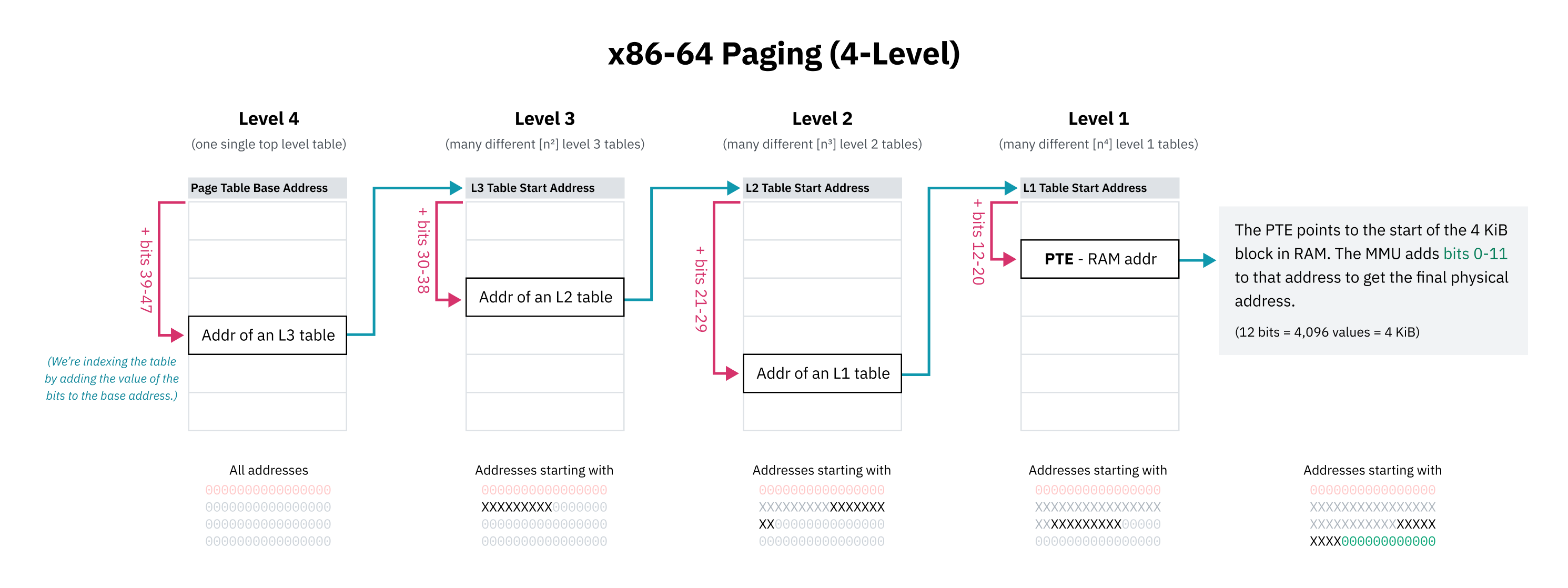
전체 가능한 가상 메모리 공간에 대해 순차 페이지 테이블 항목을 갖는 것은 불가능(또는 적어도 엄청나게 비실용적)하므로, CPU 아키텍처는 계층적 페이징을 구현합니다. 계층적 페이징 시스템에서는 점점 더 작은 세분성의 여러 수준의 페이지 테이블이 있습니다. 최상위 수준 항목은 큰 메모리 블록을 다루고 더 작은 블록의 페이지 테이블을 가리키며, 트리 구조를 만듭니다. 4 KiB 또는 페이지 크기가 무엇이든 간에 블록에 대한 개별 항목은 트리의 리프입니다.
x86-64는 역사적으로 4수준 계층적 페이징을 사용합니다. 이 시스템에서, 각 페이지 테이블 항목은 포함하는 테이블의 시작 부분에서 주소의 일부만큼 오프셋하여 찾습니다. 이 부분은 최상위 비트로 시작하며, 접두사로 작동하므로 항목은 해당 비트로 시작하는 모든 주소를 다룹니다. 항목은 해당 메모리 블록에 대한 하위 트리를 포함하는 다음 수준 테이블의 시작을 가리키며, 이것은 다음 비트 모음으로 다시 인덱싱됩니다.
x86-64의 4수준 페이징 설계자는 페이지 테이블 공간을 절약하기 위해 모든 가상 포인터의 상위 16비트를 무시하기로 선택했습니다. 48비트는 128 TiB 가상 주소 공간을 제공하며, 이것은 충분히 크다고 여겨졌습니다. (전체 64비트는 16 EiB를 제공하는데, 이것은 꽤 많습니다.)
첫 16비트는 건너뛰므로, 첫 번째 수준 페이지 테이블을 인덱싱하기 위한 “최상위 비트”는 실제로 63이 아니라 비트 47에서 시작합니다. 이것은 또한 이 장 앞부분의 상위 절반 커널 다이어그램이 기술적으로 부정확했다는 것을 의미합니다; 커널 공간 시작 주소는 64비트보다 작은 주소 공간의 중간점으로 묘사되었어야 했습니다.
계층적 페이징은 트리의 모든 수준에서 다음 항목에 대한 포인터가 null(0x0)일 수 있기 때문에 공간 문제를 해결합니다. 이것은 페이지 테이블의 전체 하위 트리를 생략할 수 있게 하며, 가상 메모리 공간의 매핑되지 않은 영역은 RAM에서 공간을 차지하지 않습니다. 매핑되지 않은 메모리 주소의 조회는 CPU가 트리에서 더 높은 곳에서 빈 항목을 보는 즉시 오류를 발생시킬 수 있기 때문에 빠르게 실패할 수 있습니다. 페이지 테이블 항목에는 주소가 유효해 보이더라도 사용할 수 없는 것으로 표시하는 데 사용할 수 있는 존재 플래그도 있습니다.
계층적 페이징의 또 다른 이점은 가상 메모리 공간의 큰 섹션을 효율적으로 교체할 수 있는 능력입니다. 큰 가상 메모리 덩어리는 한 프로세스에 대해 물리 메모리의 한 영역에 매핑될 수 있고, 다른 프로세스에 대해 다른 영역에 매핑될 수 있습니다. 커널은 두 매핑을 모두 메모리에 저장하고 프로세스를 전환할 때 트리의 최상위 수준에서 포인터를 업데이트하기만 하면 됩니다. 전체 메모리 공간 매핑이 항목의 평면 배열로 저장되면, 커널은 많은 항목을 업데이트해야 하므로 느리고 여전히 각 프로세스에 대한 메모리 매핑을 독립적으로 추적해야 합니다.
저는 x86-64가 “역사적으로” 4수준 페이징을 사용한다고 말했는데, 최근 프로세서는 5수준 페이징을 구현하기 때문입니다. 5수준 페이징은 57비트 주소로 주소 공간을 128 PiB로 확장하기 위해 또 다른 간접 계층과 9개의 주소 지정 비트를 추가합니다. 5수준 페이징은 2017년 이후 Linux와 최근 Windows 10 및 11 서버 버전을 포함한 운영 체제에서 지원됩니다.
참고: 물리 주소 공간 제한
운영 체제가 가상 주소에 모든 64비트를 사용하지 않는 것처럼, 프로세서는 전체 64비트 물리 주소를 사용하지 않습니다. 4수준 페이징이 표준이었을 때, x86-64 CPU는 46비트 이상을 사용하지 않았으며, 물리 주소 공간이 64 TiB로만 제한되었음을 의미합니다. 5수준 페이징을 사용하면, 지원이 52비트로 확장되어 4 PiB 물리 주소 공간을 지원합니다.
OS 수준에서, 가상 주소 공간이 물리 주소 공간보다 큰 것이 유리합니다. Linus Torvalds가 말했듯이, “[i]t needs to be bigger, by a factor of at least two, and that’s quite frankly pushing it, and you’re much better off having a factor of ten or more. Anybody who doesn’t get that is a moron. End of discussion.”
스와핑과 요구 페이징
메모리 액세스는 몇 가지 이유로 실패할 수 있습니다: 주소가 범위를 벗어날 수 있거나, 페이지 테이블에 매핑되지 않을 수 있거나, 존재하지 않는 것으로 표시된 항목이 있을 수 있습니다. 이러한 경우 중 어느 것이든, MMU는 커널이 문제를 처리할 수 있도록 페이지 폴트라는 하드웨어 인터럽트를 트리거합니다.
일부 경우에, 읽기가 진정으로 유효하지 않거나 금지되었습니다. 이러한 경우, 커널은 아마도 segmentation fault 오류와 함께 프로그램을 종료할 것입니다.
$ ./program
Segmentation fault (core dumped)
$참고: segfault 존재론
”Segmentation fault”는 다른 컨텍스트에서 다른 것을 의미합니다. MMU는 권한 없이 메모리를 읽을 때 “segmentation fault”라는 하드웨어 인터럽트를 트리거하지만, “segmentation fault”는 또한 OS가 불법 메모리 액세스로 인해 실행 중인 프로그램을 종료하기 위해 보낼 수 있는 신호의 이름이기도 합니다.
다른 경우에, 메모리 액세스는 의도적으로 실패할 수 있으며, OS가 메모리를 채운 다음 다시 시도하기 위해 CPU에 제어를 돌려줍니다. 예를 들어, OS는 실제로 RAM에 로드하지 않고 디스크의 파일을 가상 메모리에 매핑할 수 있으며, 주소가 요청되고 페이지 폴트가 발생할 때 물리 메모리에 로드합니다. 이것을 요구 페이징이라고 합니다.

우선, 이것은 전체 파일을 디스크에서 가상 메모리로 느리게 매핑하는 mmap과 같은 시스템 콜이 존재할 수 있게 합니다. LLaMa.cpp에 익숙하다면, 유출된 Facebook 언어 모델을 위한 런타임인데, Justine Tunney가 최근 모든 로딩 로직이 mmap을 사용하도록 만들어 크게 최적화했습니다. (그녀에 대해 들어본 적이 없다면, 그녀의 것들을 확인해보세요! Cosmopolitan Libc와 APE는 정말 멋지고 이 글을 즐기고 있다면 흥미로울 수 있습니다.)
분명히 Justine의 이 변경에 대한 참여에 대해 많은 드라마 가 있습니다. 랜덤 인터넷 사용자에게 소리지르지 않도록 이것을 지적하는 것입니다. 저는 대부분의 드라마를 읽지 않았으며, Justine의 것이 멋지다고 말한 모든 것은 여전히 매우 사실입니다.
프로그램과 라이브러리를 실행할 때, 커널은 실제로 메모리에 아무것도 로드하지 않습니다. 파일의 mmap만 생성합니다 — CPU가 코드를 실행하려고 시도하면, 페이지가 즉시 폴트하고 커널은 페이지를 실제 메모리 블록으로 교체합니다.
요구 페이징은 또한 “스와핑” 또는 “페이징”이라는 이름으로 본 적이 있을 기술을 가능하게 합니다. 운영 체제는 메모리 페이지를 디스크에 쓴 다음 물리 메모리에서 제거하지만 존재 플래그를 0으로 설정하여 가상 메모리에 유지함으로써 물리 메모리를 해제할 수 있습니다. 해당 가상 메모리가 읽히면, OS는 디스크에서 RAM으로 메모리를 복원하고 존재 플래그를 다시 1로 설정할 수 있습니다. OS는 디스크에서 로드되는 메모리를 위한 공간을 만들기 위해 RAM의 다른 섹션을 스왑해야 할 수 있습니다. 디스크 읽기 및 쓰기는 느리므로, 운영 체제는 효율적인 페이지 교체 알고리즘으로 스와핑이 가능한 한 적게 발생하도록 노력합니다.
흥미로운 해킹은 페이지 테이블 물리 메모리 포인터를 사용하여 물리 저장소 내의 파일 위치를 저장하는 것입니다. MMU가 음수 존재 플래그를 보는 즉시 페이지 폴트하므로, 그것들이 유효하지 않은 메모리 주소라는 것은 중요하지 않습니다. 이것은 모든 경우에 실용적이지는 않지만, 생각하면 재미있습니다.
챕터 6로 계속: Fork와 Cow에 대해 이야기해봅시다