Putting the “You” in CPU의 일부: 컴퓨터가 프로그램을 실행하는 방법에 대한 심층 탐구.
챕터 2:
시간을 나누다
GitHub에서 수정
운영체제(Operating System)를 만들고 있는데 사용자가 여러 프로그램을 동시에 실행할 수 있게 하고 싶다고 가정해봅시다. 하지만 멋진 멀티코어 프로세서가 없어서 CPU는 한 번에 하나의 명령어만 실행할 수 있습니다!
다행히도, 당신은 매우 똑똑한 OS 개발자입니다. CPU에서 프로세스들이 순서대로 실행되도록 하여 병렬성(parallelism)을 가짜로 만들 수 있다는 것을 알아냈습니다. 프로세스들을 순환하며 각 프로세스에서 몇 개의 명령어를 실행하면, 어떤 단일 프로세스도 CPU를 독점하지 않으면서 모든 프로세스가 반응할 수 있습니다.
그런데 프로세스를 전환하기 위해 프로그램 코드에서 어떻게 제어권을 다시 가져올까요? 약간의 연구를 해본 결과, 대부분의 컴퓨터에는 타이머 칩이 함께 제공된다는 것을 발견했습니다. 타이머 칩을 프로그래밍하여 일정 시간이 지나면 OS 인터럽트 핸들러로 전환을 트리거할 수 있습니다.
하드웨어 인터럽트(Hardware Interrupts)
앞서 소프트웨어 인터럽트(software interrupts)가 사용자 영역 프로그램에서 OS로 제어권을 넘기는 데 어떻게 사용되는지 이야기했습니다. 이것들이 “소프트웨어” 인터럽트라고 불리는 이유는 프로그램에 의해 자발적으로 트리거되기 때문입니다 — 정상적인 fetch-execute 사이클에서 프로세서가 실행하는 기계 코드가 커널로 제어권을 전환하라고 지시합니다.
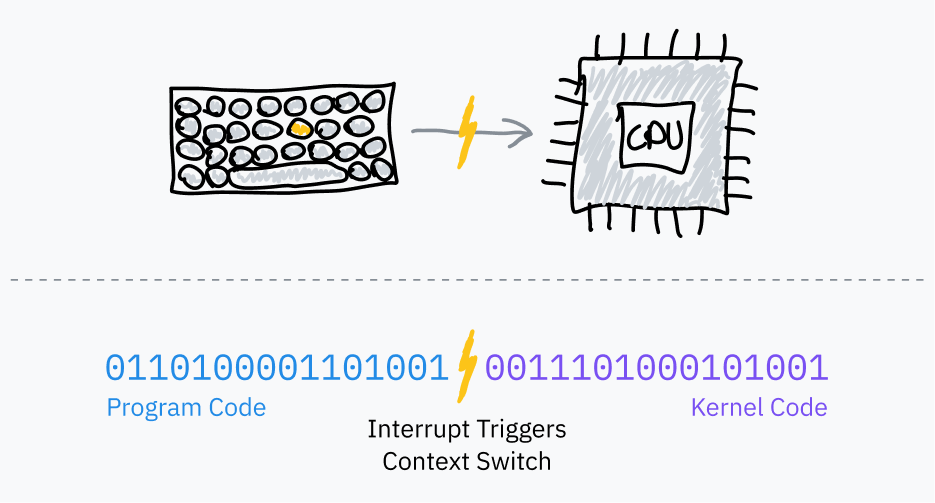
OS 스케줄러는 멀티태스킹을 위해 PIT와 같은 타이머 칩을 사용하여 하드웨어 인터럽트를 트리거합니다:
- 프로그램 코드로 점프하기 전에, OS는 타이머 칩을 설정하여 일정 시간 후 인터럽트를 트리거하도록 합니다.
- OS는 사용자 모드로 전환하고 프로그램의 다음 명령어로 점프합니다.
- 타이머가 경과하면, 커널 모드로 전환하고 OS 코드로 점프하는 하드웨어 인터럽트를 트리거합니다.
- 이제 OS는 프로그램이 중단된 위치를 저장하고, 다른 프로그램을 로드하고, 프로세스를 반복할 수 있습니다.
이것을 *선점형 멀티태스킹(preemptive multitasking)*이라고 합니다; 프로세스의 중단을 선점(preemption)이라고 합니다. 예를 들어, 같은 기계에서 브라우저로 이 글을 읽으면서 음악을 듣고 있다면, 당신의 컴퓨터는 아마도 초당 수천 번 이 정확한 사이클을 따르고 있을 것입니다.
타임슬라이스 계산(Timeslice Calculation)
*타임슬라이스(timeslice)*는 OS 스케줄러가 프로세스를 선점하기 전에 프로세스가 실행되도록 허용하는 시간입니다. 타임슬라이스를 선택하는 가장 간단한 방법은 모든 프로세스에 동일한 타임슬라이스를 제공하는 것입니다. 아마도 10 ms 범위에서 순서대로 작업을 순환하는 것입니다. 이것을 고정 타임슬라이스 라운드 로빈(fixed timeslice round-robin) 스케줄링이라고 합니다.
참고: 재미있는 전문 용어 사실!
타임슬라이스를 종종 “quantum”이라고 부른다는 것을 알고 계셨나요? 이제 아셨으니, 모든 기술 친구들에게 깊은 인상을 줄 수 있습니다. 저는 이 글의 모든 문장마다 quantum이라고 말하지 않은 것에 대해 많은 칭찬을 받을 자격이 있다고 생각합니다.
타임슬라이스 전문 용어에 대해 말하자면, 리눅스 커널 개발자들은 고정 주파수 타이머 틱을 세기 위해 jiffy 시간 단위를 사용합니다. 무엇보다도, jiffy는 타임슬라이스의 길이를 측정하는 데 사용됩니다. 리눅스의 jiffy 주파수는 일반적으로 1000 Hz이지만 커널을 컴파일할 때 구성할 수 있습니다.
고정 타임슬라이스 스케줄링에 대한 약간의 개선은 *목표 지연 시간(target latency)*을 선택하는 것입니다 — 프로세스가 응답하는 데 이상적인 가장 긴 시간입니다. 목표 지연 시간은 합리적인 수의 프로세스를 가정할 때 프로세스가 선점된 후 실행을 재개하는 데 걸리는 시간입니다. 이것은 시각화하기가 매우 어렵습니다! 걱정하지 마세요, 곧 다이어그램이 나옵니다.
타임슬라이스는 목표 지연 시간을 총 작업 수로 나누어 계산됩니다; 이것은 프로세스가 적을 때 낭비적인 작업 전환을 제거하기 때문에 고정 타임슬라이스 스케줄링보다 낫습니다. 목표 지연 시간이 15 ms이고 프로세스가 10개인 경우, 각 프로세스는 15/10 또는 1.5 ms를 실행합니다. 프로세스가 3개만 있으면, 각 프로세스는 목표 지연 시간을 여전히 충족하면서 더 긴 5 ms 타임슬라이스를 얻습니다.
프로세스 전환은 현재 프로그램의 전체 상태를 저장하고 다른 프로그램을 복원해야 하므로 계산적으로 비용이 많이 듭니다. 특정 지점을 넘어서면, 너무 작은 타임슬라이스는 프로세스가 너무 빠르게 전환되어 성능 문제를 일으킬 수 있습니다. 타임슬라이스 기간에 하한(최소 세분성, minimum granularity)을 부여하는 것이 일반적입니다. 이것은 최소 세분성이 효과를 발휘할 만큼 충분한 프로세스가 있을 때 목표 지연 시간이 초과된다는 것을 의미합니다.
이 글을 쓰는 시점에서, 리눅스의 스케줄러는 6 ms의 목표 지연 시간과 0.75 ms의 최소 세분성을 사용합니다.
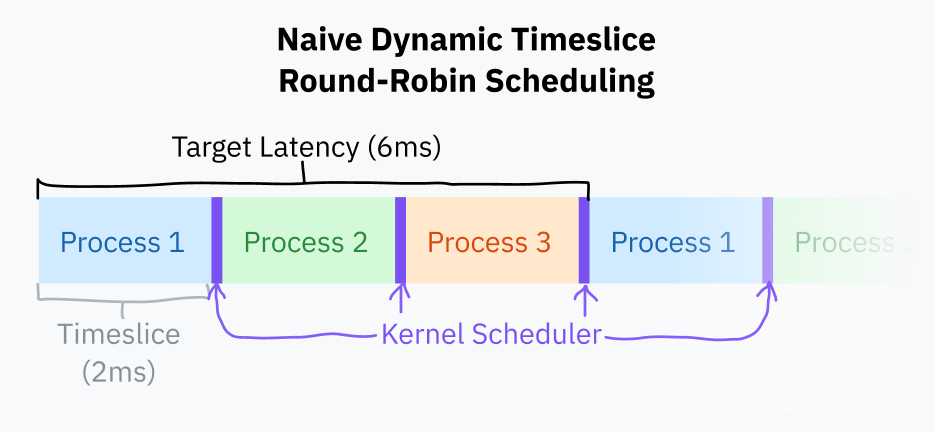
이 기본적인 타임슬라이스 계산을 사용하는 라운드 로빈 스케줄링은 요즘 대부분의 컴퓨터가 하는 것과 비슷합니다. 여전히 약간 순진합니다; 대부분의 운영체제는 프로세스 우선순위와 데드라인을 고려하는 더 복잡한 스케줄러를 가지는 경향이 있습니다. 2007년부터 리눅스는 완전 공정 스케줄러(Completely Fair Scheduler)라는 스케줄러를 사용하고 있습니다. CFS는 작업의 우선순위를 정하고 CPU 시간을 나누기 위해 매우 멋진 컴퓨터 과학적인 것들을 많이 합니다.
OS가 프로세스를 선점할 때마다 가상 주소에서 물리 주소로의 매핑인 *페이지 테이블(page table)*을 포함하여 새 프로그램의 저장된 실행 컨텍스트를 로드해야 합니다. 이것은 CPU에게 다른 페이지 테이블을 사용하라고 지시함으로써 달성됩니다. 이것은 또한 프로그램이 서로의 메모리에 액세스하는 것을 방지하는 시스템입니다; 우리는 이 글의 5장과 6장에서 이 토끼굴로 내려갈 것입니다.
참고 사항 #1: 커널 선점성(Kernel Preemptability)
지금까지 우리는 사용자 영역 프로세스의 선점과 스케줄링에 대해서만 이야기했습니다. 커널 코드가 시스템 콜을 처리하거나 드라이버 코드를 실행하는 데 너무 오래 걸리면 프로그램이 느리게 느껴질 수 있습니다.
리눅스를 포함한 현대 커널은 선점형 커널(preemptive kernels)입니다. 이것은 커널 코드 자체가 사용자 영역 프로세스처럼 인터럽트되고 스케줄링될 수 있는 방식으로 프로그래밍되었다는 것을 의미합니다.
커널이나 무언가를 작성하지 않는 한 이것을 아는 것은 그다지 중요하지 않지만, 기본적으로 제가 읽은 모든 글에서 언급했기 때문에 저도 언급하려고 합니다! 추가 지식이 나쁜 것은 거의 없습니다.
참고 사항 #2: 역사 수업
고전적인 Mac OS와 NT 이전의 Windows 버전을 포함한 고대 운영체제는 선점형 멀티태스킹의 전신을 사용했습니다. OS가 프로그램을 선점할 시기를 결정하는 대신, 프로그램 자체가 OS에 양보하기로 선택했습니다. 프로그램은 소프트웨어 인터럽트를 트리거하여 “이봐요, 이제 다른 프로그램을 실행할 수 있어요”라고 말했습니다. 이러한 명시적 양보는 OS가 제어권을 되찾고 다음 예약된 프로세스로 전환하는 유일한 방법이었습니다.
이것을 협력적 멀티태스킹(cooperative multitasking)이라고 합니다. 이것은 몇 가지 주요 결함이 있습니다: 악의적이거나 단지 잘못 설계된 프로그램이 전체 운영체제를 쉽게 동결시킬 수 있으며, 실시간/시간에 민감한 작업에 대한 시간적 일관성을 보장하는 것이 거의 불가능합니다. 이러한 이유로, 기술 세계는 오래 전에 선점형 멀티태스킹으로 전환했고 결코 되돌아보지 않았습니다.
챕터 3로 계속: 프로그램 실행 방법